Expression: The aircraft that is most likely to be low on fuel.
Method
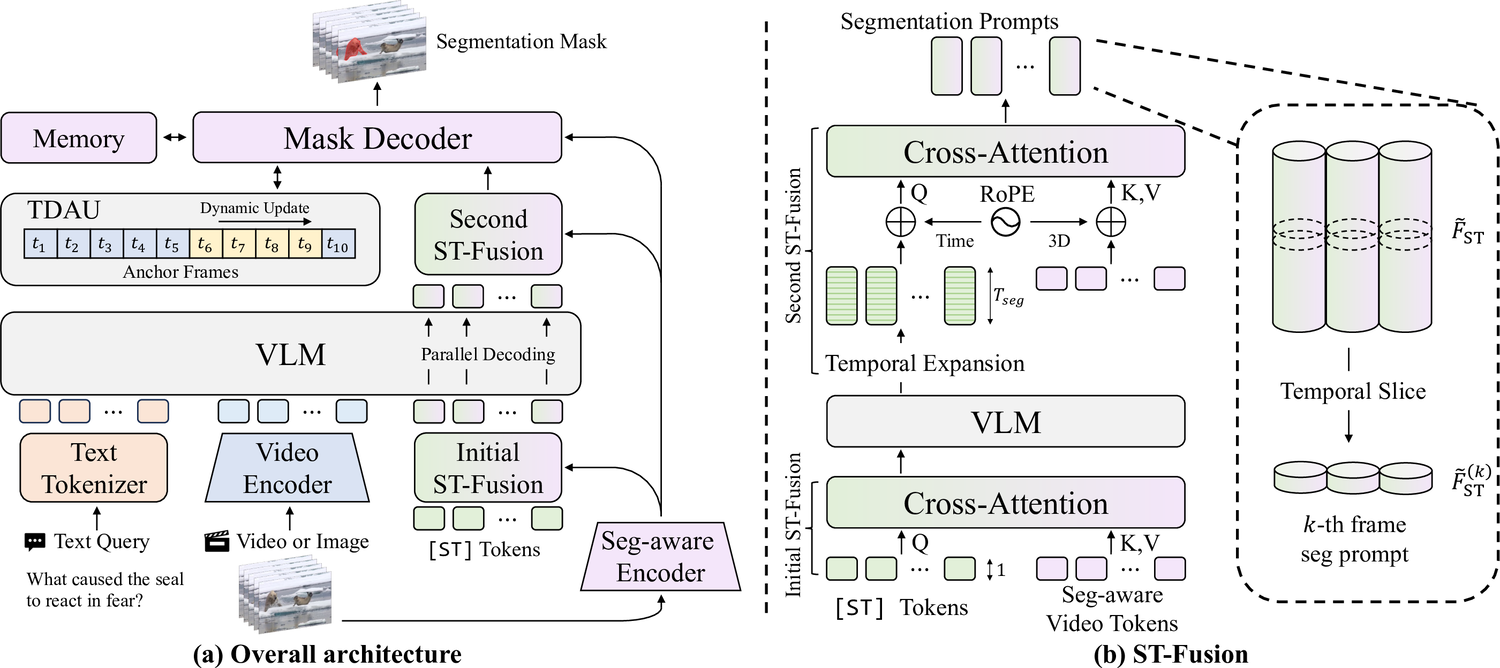
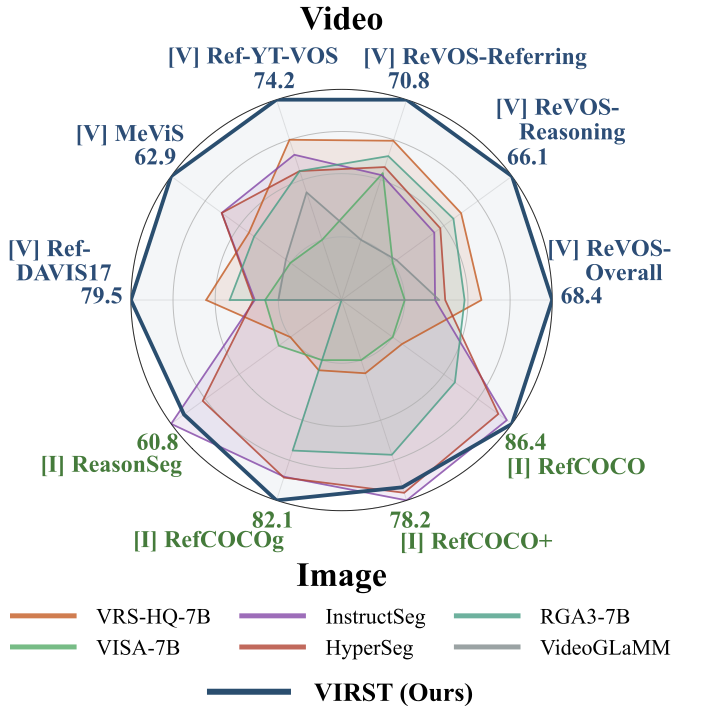
VIRST unifies video-level reasoning and pixel-level mask prediction in a single end-to-end RVOS framework. Instead of relying on a fixed keyframe or an external propagation pipeline, VIRST lets the vision-language model reason over the video while segmentation-aware features provide the spatial detail needed for accurate masks.
Spatio-Temporal Fusion
STF bridges semantic video tokens and dense segmentation features. Learnable [ST] tokens are fused with segmentation-aware video features before and after VLM reasoning, producing frame-specific prompts for the mask decoder.
Dynamic Anchors
TDAU maintains multiple temporally nearby anchor frames and updates them as the video progresses. This gives the decoder stable cues under large motion, occlusion, and object reappearance.
Progressive Training
Training gradually aligns language reasoning, spatial grounding, and temporal consistency so the unified model can handle both referring and reasoning-oriented video segmentation.