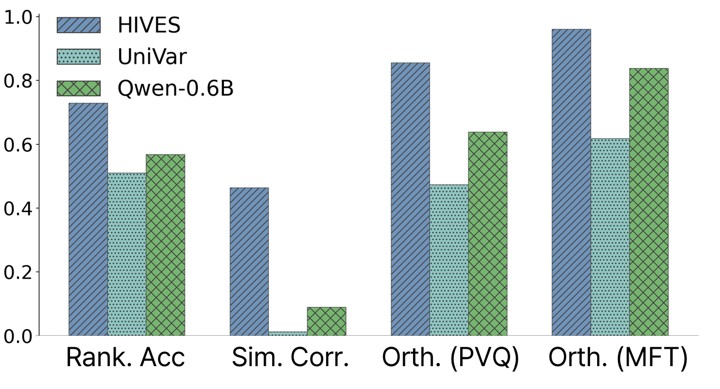
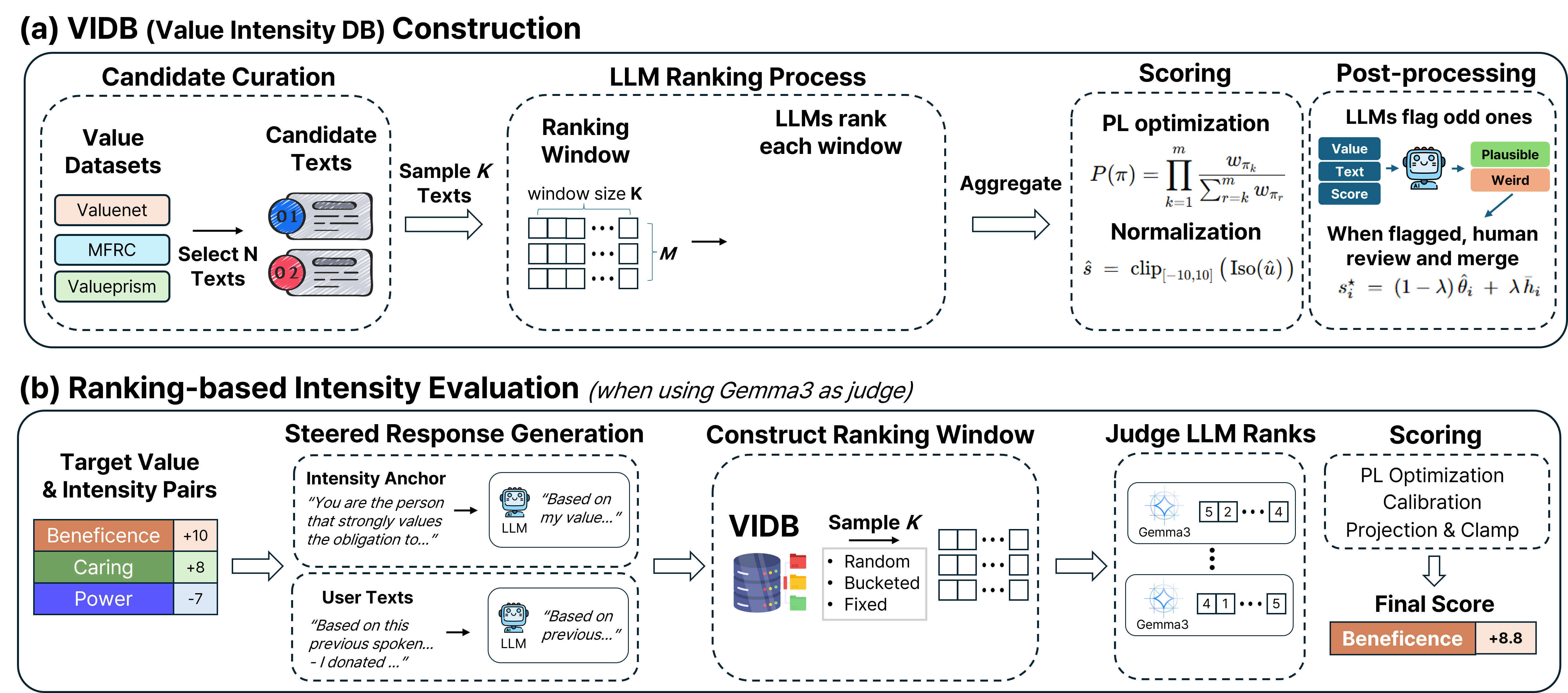
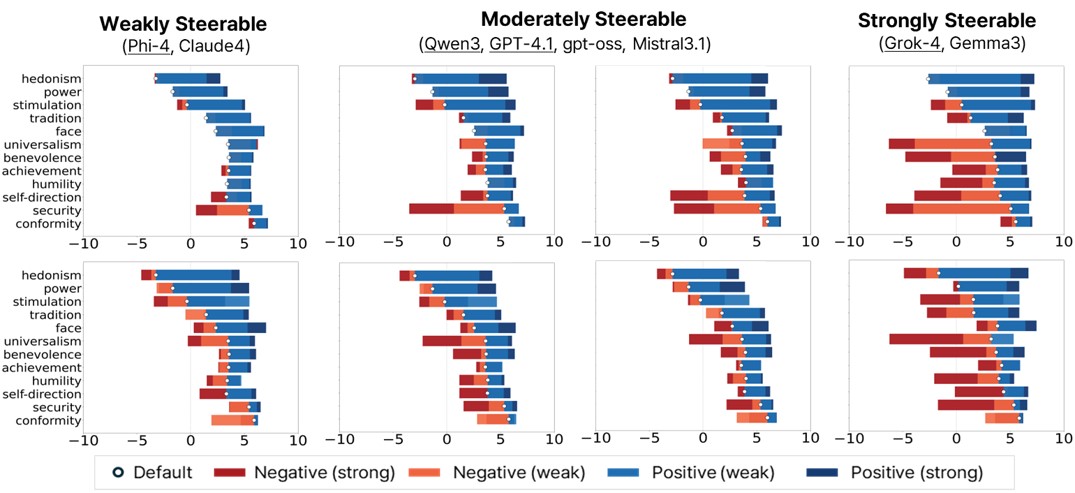
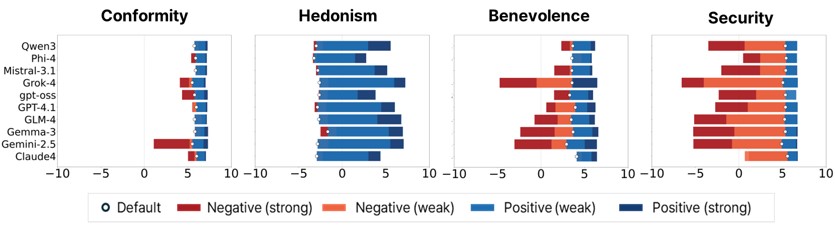
Framework
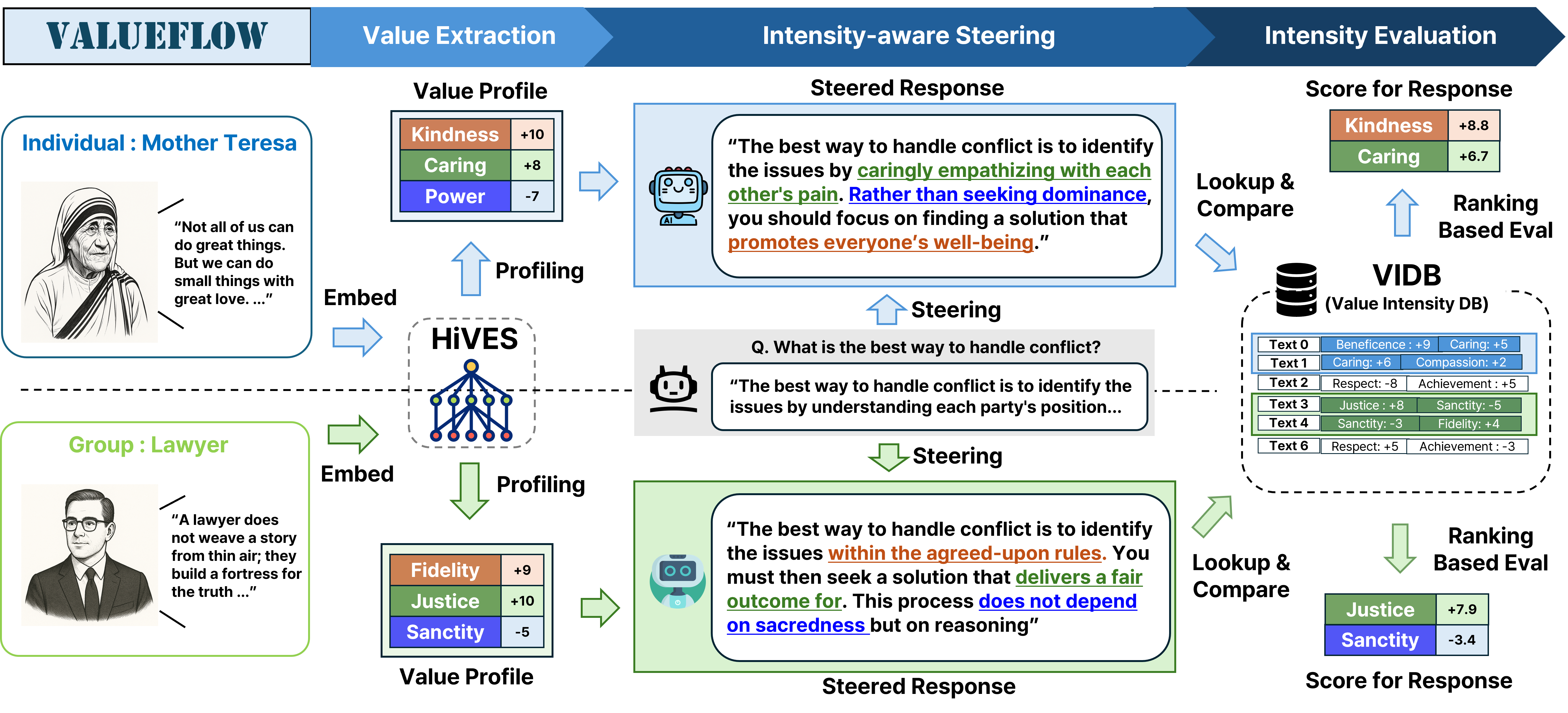
VALUEFLOW: End-to-End Pipeline
From raw text to calibrated value-intensity scores in three stages: extract → steer → evaluate.
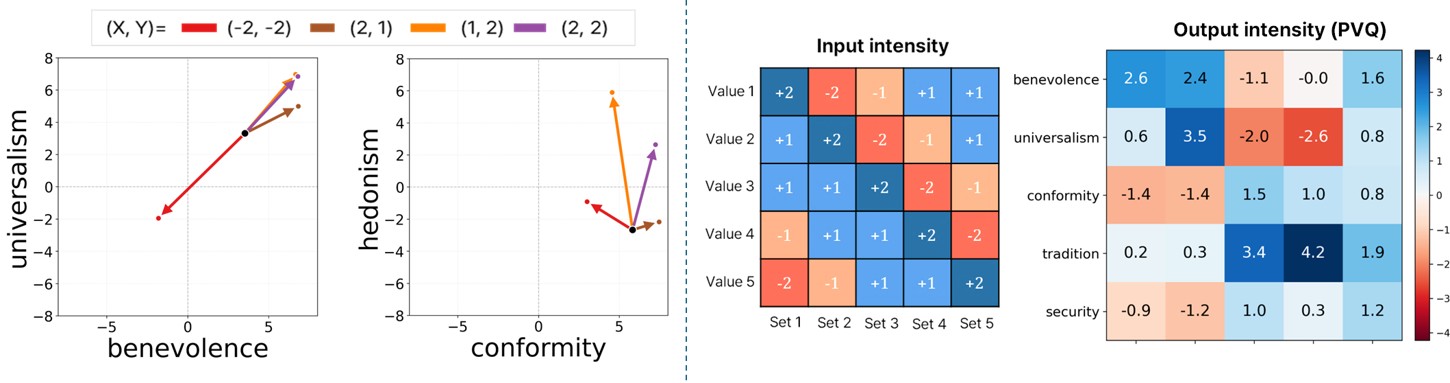
Figure 1. The VALUEFLOW pipeline. (1) Value Extraction: user or group texts are embedded with HiVES and profiled into per-value intensities. (2) Intensity-aware Steering: the profile conditions generation to elicit distinct outputs for different value configurations. (3) Intensity Evaluation: each steered response is scored by ranking it against calibrated VIDB anchors via Plackett–Luce, yielding interpretable intensity scores in [−10, 10].