Vector databases are now a core substrate for modern retrieval systems,
including Retrieval-Augmented Generation pipelines. Their search layer must
satisfy several demands at once: high recall, high throughput, bounded latency,
manageable build time, and compact index size. HNSW is widely adopted because
it offers an attractive recall-latency trade-off, yet its three central knobs,
M, efc, and efs, interact in nonlinear ways that
make production tuning costly and brittle.
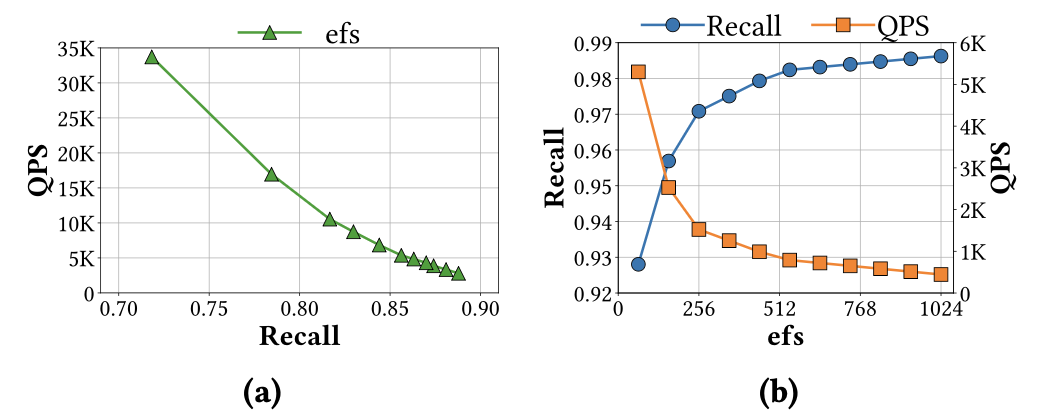
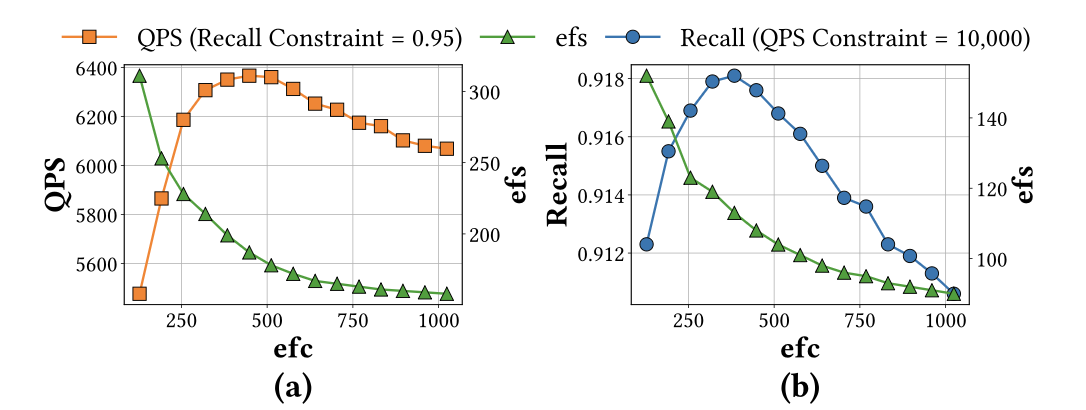
This paper shows that the HNSW search space is not arbitrary. Query-time
candidate expansion induces monotone feasibility boundaries; construction-time
parameters exhibit dominant unimodal behavior after the search boundary is
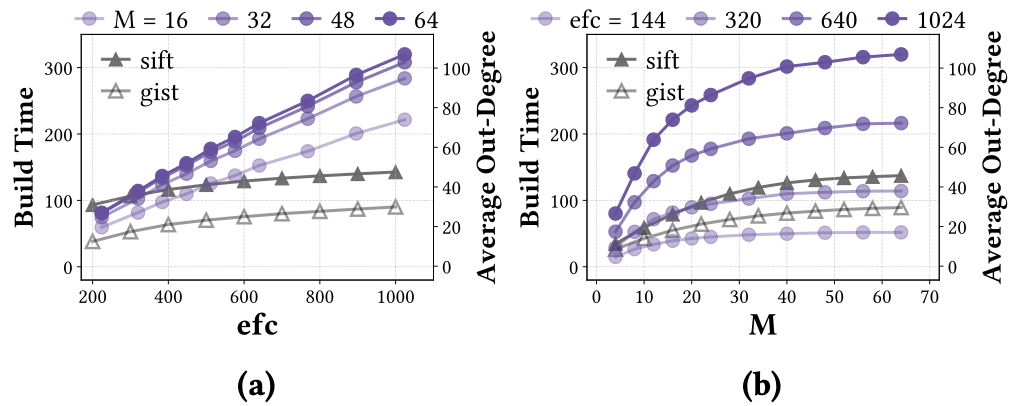
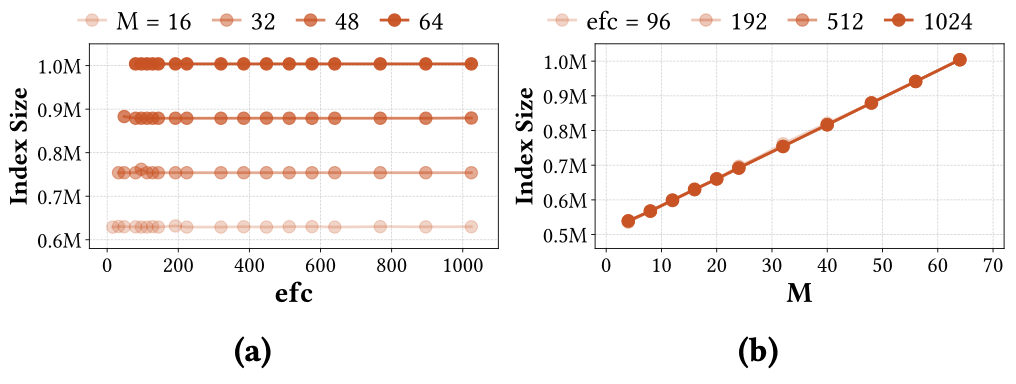
selected; and resource usage separates into compact build-time and index-size
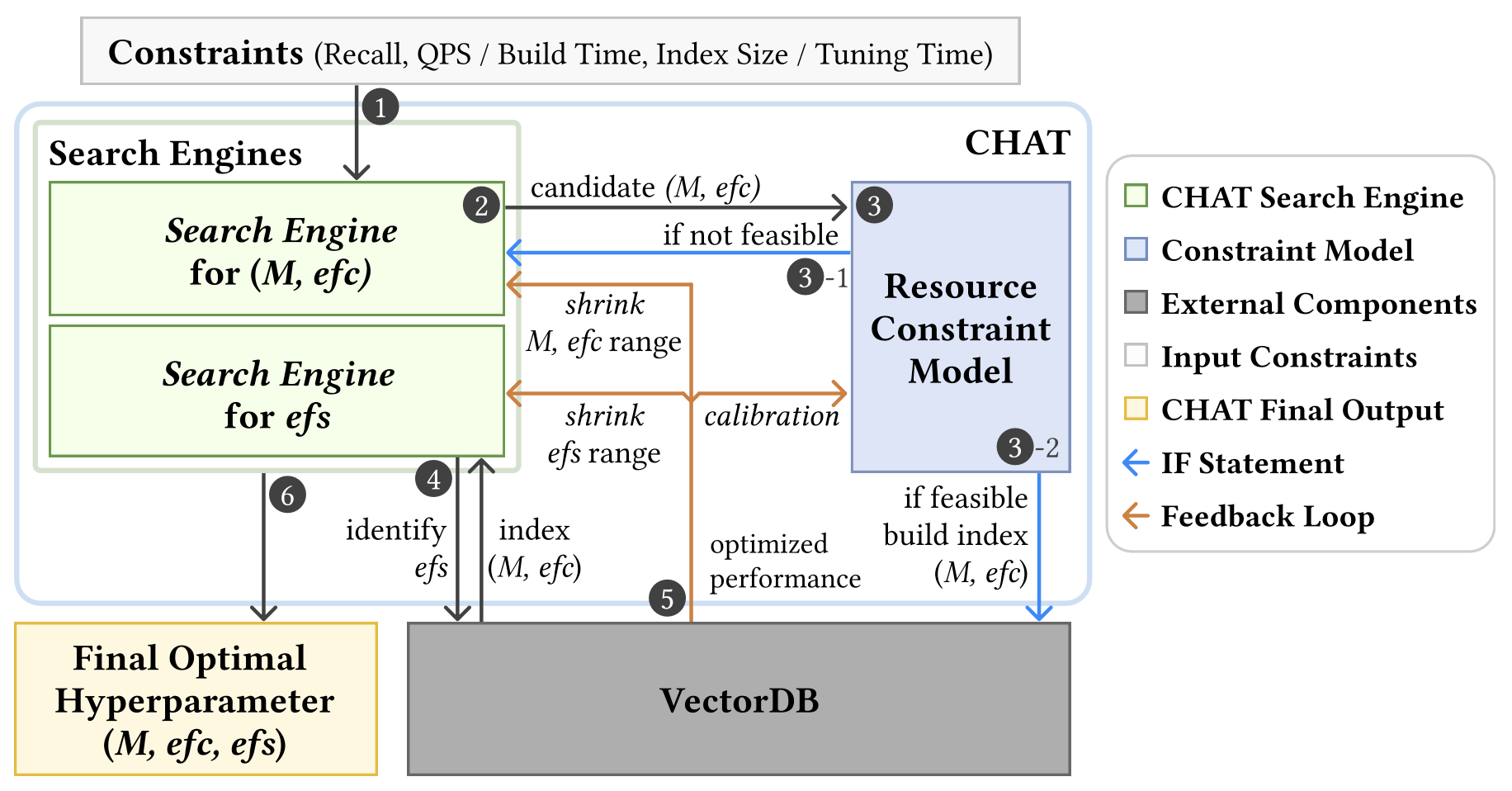
dependencies. CHAT uses these structural regularities to tune HNSW with
deterministic, sample-efficient search while pruning resource-infeasible
configurations before full index construction.
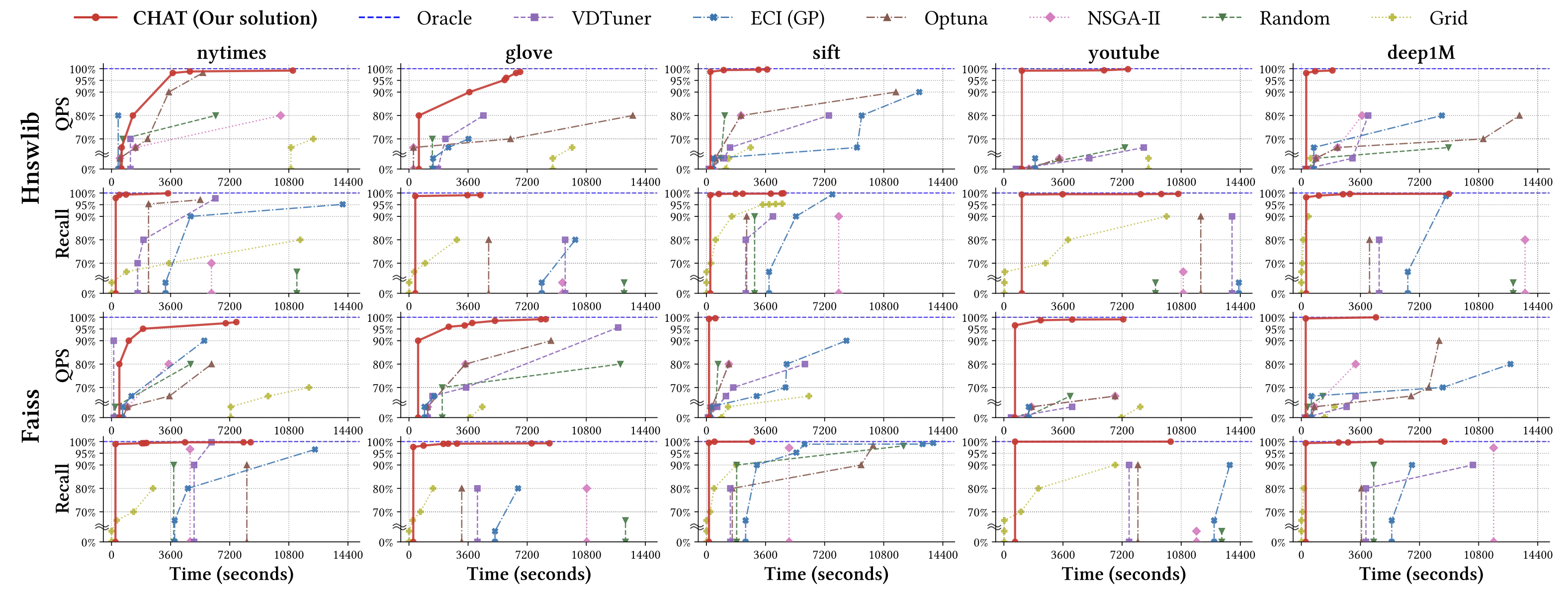
Across multiple datasets and HNSW-based vector search engines, CHAT finds
configurations that maximize Recall or QPS while satisfying constraints on
accuracy, throughput, build time, index size, and tuning budget.